Технологии программирования
Главная / Лекция 8. Spring Framework. JPA. Hibernate
Лекция 8. Spring Framework. JPA. Hibernate (Advanced)
Содержание
- Object-relational impedance mismatch
- Модель данных и транзакции
- JPA как абстракция
- Hibernate: как это реально работает
- Проблемы ORM
- Spring Data JPA
- JOOQ
- Trade-offs
1. Object-relational impedance mismatch
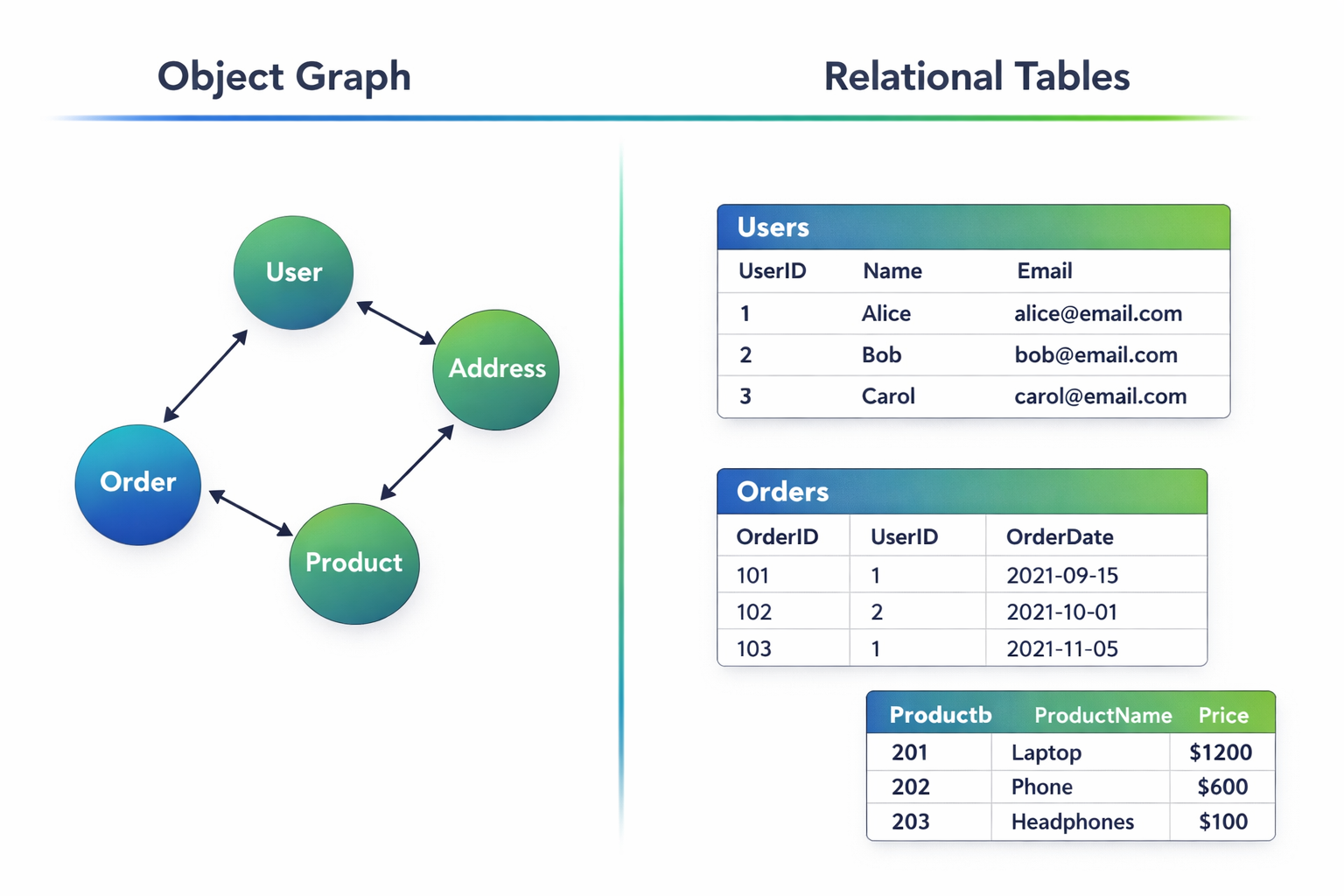
В коде мы работаем с объектами и ссылками между ними, а в базе данных — с таблицами, строками и внешними ключами. Эти модели не совпадают напрямую. Этот разрыв между объектной и реляционной моделью называется object-relational impedance mismatch.
В коде данные представлены как:
- объекты, связанные друг с другом через ссылки
- графы объектов
- вложенные структуры
В базе данных данные организованы как:
- таблицы
- строки
- связи через внешние ключи
Например:
- в коде:
User -> List<Order> - в базе: две таблицы + JOIN
Каждый раз при работе с базой приходится:
- превращать строки в объекты
- собирать граф объектов вручную
- следить за согласованностью данных
2. Модель данных и транзакции
Работа с базой — это не только получение данных, но и управление состоянием системы.
ACID
Любая транзакционная СУБД гарантирует:
- Atomicity — либо все, либо ничего
- Consistency — данные остаются корректными
- Isolation — транзакции не мешают друг другу
- Durability — изменения не теряются
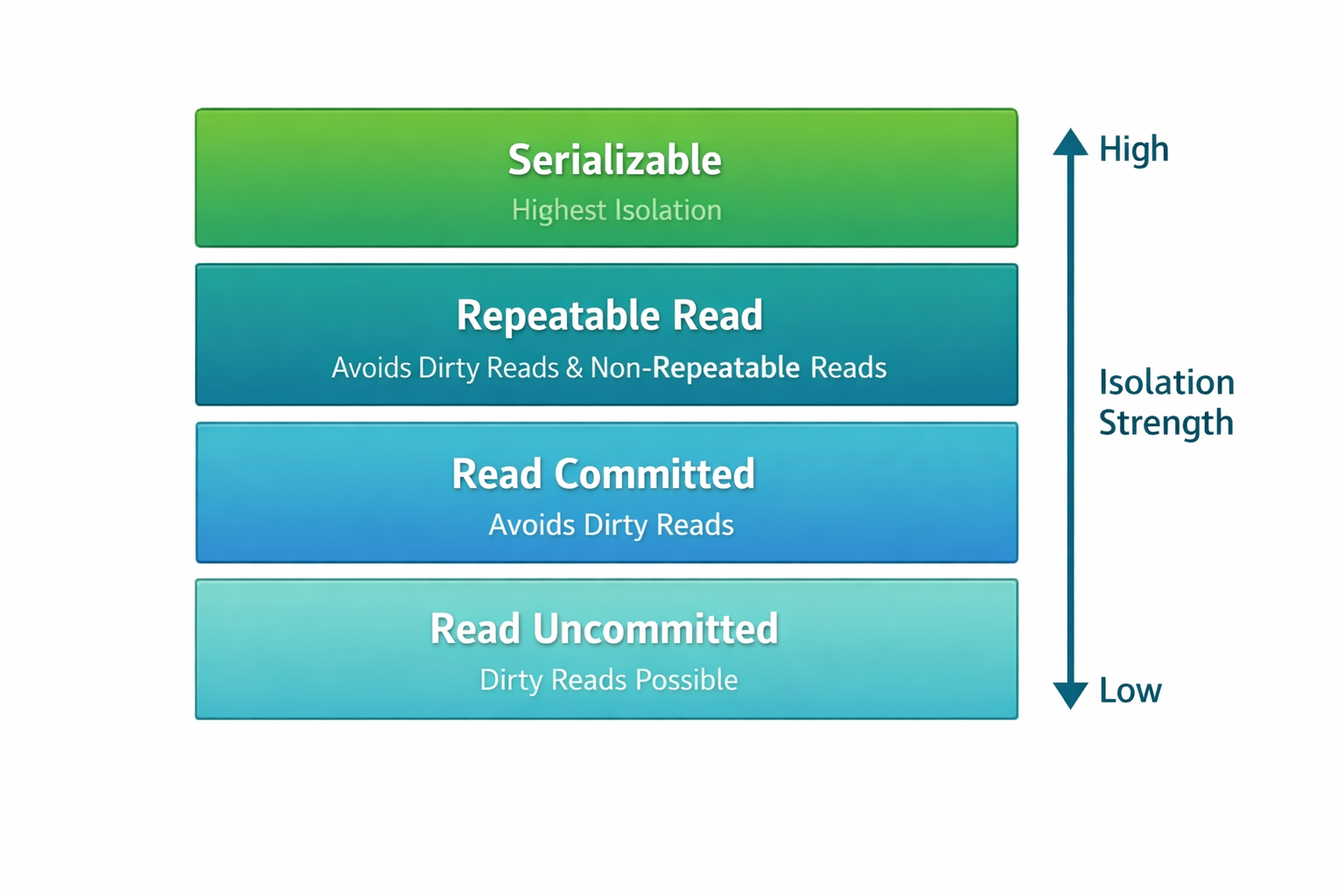
Уровни изоляции
Разные уровни изоляции дают разное поведение:
- Read Committed — читаем только подтвержденные данные
- Repeatable Read — данные не меняются в рамках транзакции
- Serializable — полная изоляция
Для backend-разработчика важно понимать, что ORM работает не “вместо” транзакционной модели базы, а поверх нее. Hibernate и JPA упрощают доступ к данным, но корректность изменений по-прежнему определяется транзакциями, изоляцией и поведением самой СУБД.
3. JPA как абстракция
JPA (Java Persistence API) — это спецификация платформы Java Enterprise / Jakarta EE для работы с реляционными данными в Java-приложениях. Она задает API и правила поведения, но не содержит собственной реализации.
JPA исторически входил в Java EE, а сейчас относится к Jakarta Persistence. Основные API находятся в пакетах javax.persistence (исторически) и jakarta.persistence (современные версии).
На практике JPA опирается на аннотации для описания сущностей и на EntityManager для работы с ними.
Основная идея
Вместо прямого написания SQL мы работаем с объектами, а JPA-провайдер (например, Hibernate) берет на себя преобразование между объектной и реляционной моделями.
Persistence Context
Ключевая концепция JPA — это Persistence Context — механизм, который обеспечивает согласованность между объектами в памяти и данными в базе.
Обычно persistence context существует вместе с EntityManager: когда создается EntityManager, вместе с ним появляется и область управляемых сущностей. Пока сущность находится внутри этого контекста, Hibernate/JPA может отслеживать ее изменения и синхронизировать их с базой.
Что это такое
Persistence Context — это набор сущностей, которыми управляет JPA в рамках одной сессии работы с базой. Это “область”, внутри которой:
- объекты считаются управляемыми (managed)
- изменения отслеживаются
- обеспечивается идентичность объектов
Основные свойства
1. Identity Map
Внутри Persistence Context действует правило: одна запись в БД = один объект в памяти
User u1 = entityManager.find(User.class, 1);
User u2 = entityManager.find(User.class, 1);
u1 == u2 // true
2. Управляемые сущности (Managed state)
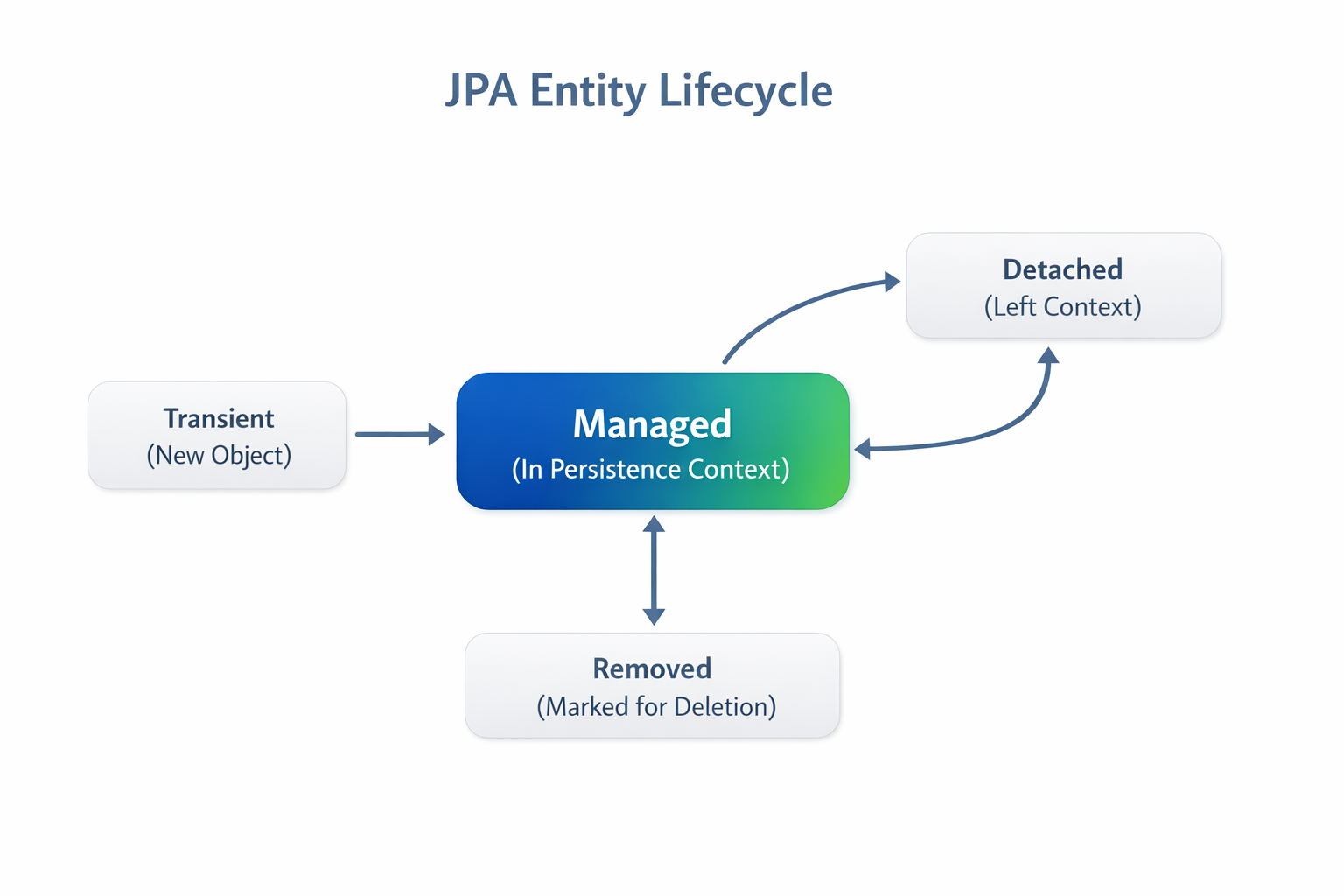
Сущности бывают в разных состояниях:
- Transient — просто создан объект
- Managed — находится в Persistence Context
- Detached — был управляемым, но вышел из контекста
- Removed — помечен на удаление
Только managed-сущности отслеживаются для автоматической синхронизации изменений.
3. Dirty Checking
Persistence Context отслеживает изменения объектов:
user.setName("new");
При commit JPA сам сгенерирует SQL для синхронизации изменений.
4. Hibernate: как это реально работает
Что это такое
Hibernate — это полноценная ORM-библиотека, которая реализует спецификацию JPA. Важно различать уровни:
- JPA — это спецификация (контракт, набор правил)
- Hibernate — конкретная реализация этой спецификации
В экосистеме Spring Hibernate используется внутри Spring Data JPA как реализация по умолчанию.
Что делает Hibernate
Hibernate берет на себя преобразование объектной модели приложения в реляционную модель базы данных:
- преобразует объекты в SQL-запросы
- преобразует ResultSet обратно в объекты
- управляет жизненным циклом сущностей
- реализует Persistence Context
- отслеживает изменения (dirty checking)
- управляет загрузкой данных (lazy/eager)
С практической точки зрения Hibernate берет объектную модель приложения и делает ее рабочей по отношению к базе данных: он понимает аннотации сущностей, хранит управляемые объекты в persistence context, отслеживает изменения и в нужный момент генерирует SQL.
В приложениях на Spring транзакциями обычно управляет Spring, а Hibernate работает внутри этих транзакций и синхронизирует состояние сущностей с базой.
Практический пример (единый через весь блок)
Будем использовать модель:
- User (пользователь)
- Order (заказ)
Это классическая one-to-many связь.
Сущности
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Order> orders;
}
@Entity
@Table(name = "orders")
public class Order {
@Id
@GeneratedValue
private Long id;
private String description;
@ManyToOne
@JoinColumn(name = "user_id")
private User user;
}
Здесь важно понимать:
mappedByговорит, что связь управляется другой стороной@JoinColumnопределяет внешний ключLAZYозначает, что данные подгружаются по требованию
Как подключить Hibernate
Gradle зависимости
В современном Spring-проекте напрямую Hibernate почти не подключают.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.postgresql:postgresql'
}
Spring Boot starter уже содержит Hibernate — вы не работаете напрямую с Hibernate, но он выполняет всю работу.
Настройка подключения к базе
spring:
datasource:
url: jdbc:postgresql://localhost:5432/app
username: user
password: password
jpa:
hibernate:
ddl-auto: update
show-sql: true
Для учебных и небольших демонстрационных проектов ddl-auto: update удобен, потому что Hibernate может автоматически подстраивать схему. В production такой режим обычно избегают и используют миграции.
Связи между сущностями
Hibernate поддерживает все основные типы связей. Связи между сущностями определяют не только структуру модели, но и то, какие SQL-запросы будет строить Hibernate. Поэтому при проектировании связей важно думать не только о предметной области, но и о последствиях для загрузки данных.
One-to-Many / Many-to-One
Самая распространенная связь:
@OneToMany(mappedBy = "user")
List<Order> orders;
@ManyToOne
User user;
Один пользователь — много заказов. Каждый заказ — один пользователь.
One-to-One
@OneToOne
@JoinColumn(name = "profile_id")
Profile profile;
Один к одному — используется реже, обычно для расширения сущности.
Many-to-Many
@ManyToMany
@JoinTable(
name = "user_roles",
joinColumns = @JoinColumn(name = "user_id"),
inverseJoinColumns = @JoinColumn(name = "role_id")
)
List<Role> roles;
Реализуется через промежуточную таблицу.
N+1 проблема
Это одна из самых частых проблем при использовании Hibernate.
Пример:
List<User> users = userRepository.findAll();
for (User u : users) {
u.getOrders().size();
}
Что происходит:
- Hibernate делает запрос за пользователями
- Затем для каждого пользователя делает отдельный запрос за заказами
N+1 возникает не просто потому, что “Hibernate плохой”, а потому что при ленивой загрузке (LAZY) связанные данные не приходят сразу. Когда код начинает обращаться к этим связям в цикле, Hibernate вынужден выполнять дополнительные запросы — по одному на каждый объект.

Решение: EntityGraph
По умолчанию Hibernate управляет загрузкой связей через стратегии LAZY и EAGER.
Если используется LAZY, связанные данные (например, orders) не загружаются сразу — и при обращении к ним возникает N+1 проблема (много отдельных запросов). Если использовать EAGER, Hibernate всегда будет подтягивать связи, даже если они не нужны — это приводит к over-fetching.
EntityGraph — это способ локально переопределить стратегию загрузки для конкретного запроса. Он полезен тогда, когда по умолчанию связь остается LAZY, но в одном конкретном сценарии данные нужно загрузить заранее, чтобы избежать лишних запросов.
@EntityGraph(attributePaths = {"orders"})
List<User> findAll();
EntityGraph позволяет явно указать, какие связи нужно загрузить вместе с основной сущностью. На практике это часто приводит к более эффективной стратегии загрузки и помогает избежать N+1, но конкретный SQL зависит от реализации и выбранной стратегии fetch.
5. Проблемы ORM
Hibernate часто вызывает споры в индустрии. Проблемы ORM — это не “баги Hibernate”, а следствие высокой абстракции.
ORM делает разработку быстрее, пока модель данных и сценарии просты. Но чем сложнее система и чем важнее контроль над SQL, тем сильнее проявляется цена абстракции. Именно поэтому споры вокруг Hibernate обычно касаются не самого факта его существования, а границ его применимости.
Плюсы
- ускоряет разработку
- уменьшает количество кода
- интегрируется со Spring
- позволяет мыслить в терминах объектов
Минусы
1. Потеря прозрачности
Разработчик не всегда понимает:
- какой SQL выполняется
- сколько запросов идет в базу
2. Скрытая сложность
Под капотом:
- lazy loading
- persistence context
- кеш
- прокси
Все это влияет на поведение системы.
3. Производительность
Ошибки вроде:
- N+1
- лишних JOIN
- неоптимальных запросов
проявляются только под нагрузкой.
6. Spring Data JPA
Spring Data JPA — это библиотека из экосистемы Spring, которая добавляет репозиторную абстракцию поверх JPA. Она не заменяет JPA и не реализует ORM самостоятельно, а упрощает типовые сценарии доступа к данным: CRUD-операции, пагинацию, сортировку и простые запросы.
Пример
Entity
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue
private Long id;
private String name;
private String email;
}
public interface UserRepository extends JpaRepository<User, Long> {
// простой метод — генерируется автоматически
List<User> findByName(String name);
// кастомный запрос
@Query("SELECT u FROM User u WHERE u.email LIKE %:email%")
List<User> searchByEmail(@Param("email") String email);
}
@Service
public class UserService {
private final UserRepository userRepository;
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public void example() {
// простой запрос
List<User> users = userRepository.findByName("Alex");
// кастомный запрос
List<User> emails = userRepository.searchByEmail("gmail");
}
}
Когда использовать
- CRUD операции
- простые фильтры
- быстрый старт
7. JOOQ
Что это такое
jOOQ — это Java-библиотека для типобезопасной работы с SQL. Название расшифровывается как Java Object Oriented Querying.
Если ORM старается скрыть реляционную природу базы за объектной моделью, то jOOQ, наоборот, принимает ее как данность и дает удобный способ работать с SQL почти без потери выразительности и контроля.
Важно понимать его место в экосистеме:
- jOOQ — это не ORM
- jOOQ — это SQL DSL (domain-specific language для написания SQL в коде)
- jOOQ не пытается скрыть реляционную модель, а наоборот — позволяет работать с ней более удобно и безопасно
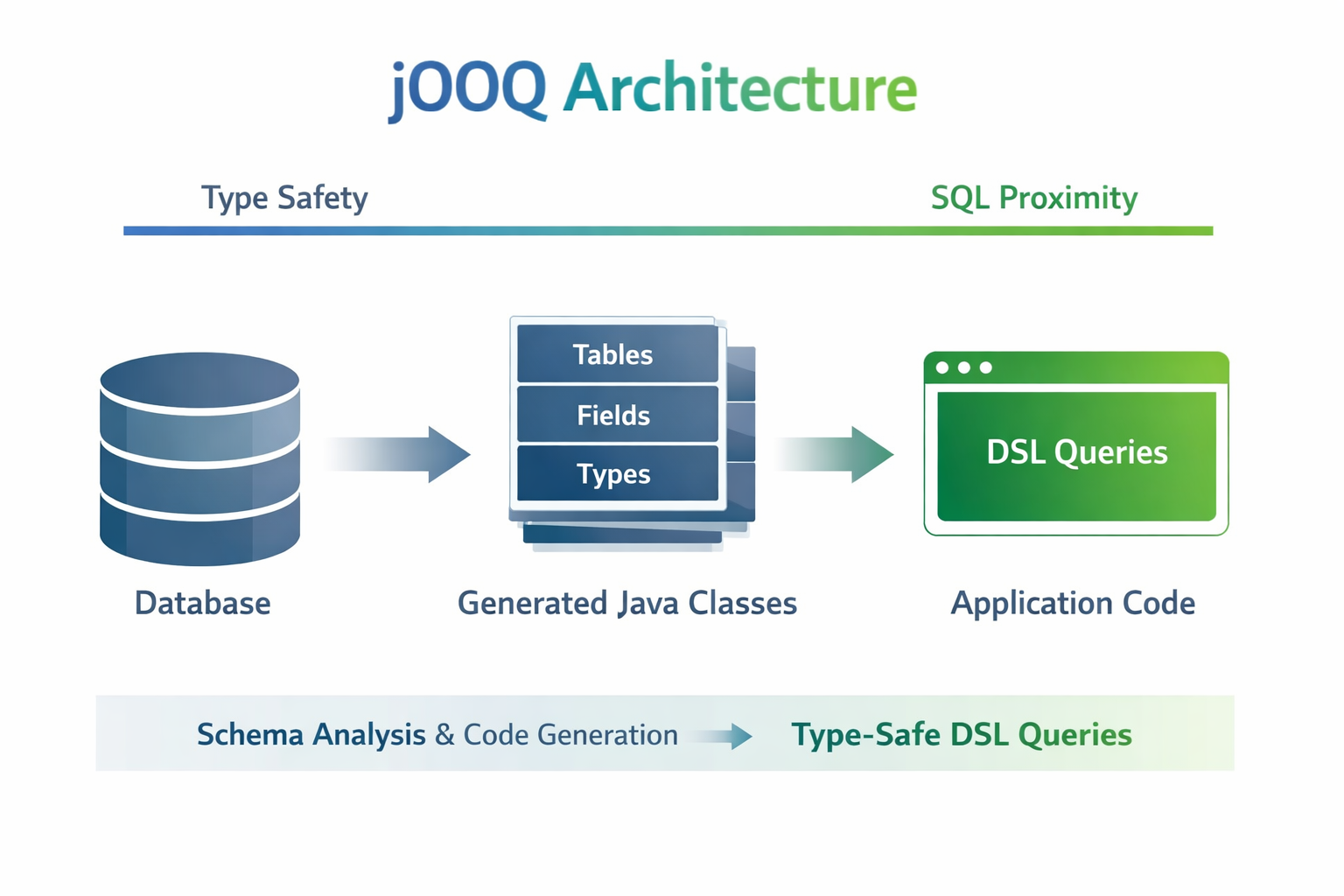
Принцип работы
Главная идея jOOQ состоит в том, что структура базы данных сначала генерируется в виде Java-классов, а затем эти классы используются для построения запросов.
Например, если в базе есть таблица users, то jOOQ сгенерирует для нее Java-описание:
- таблицу
USERS - поля
USERS.ID,USERS.NAME,USERS.EMAIL - типы данных этих полей
После этого запросы можно писать не строками, а через DSL:
var result = dsl
.select(USERS.ID, USERS.NAME)
.from(USERS)
.where(USERS.NAME.eq("Alex"))
.fetch();
Это дает несколько важных эффектов:
- запросы становятся типобезопасными
- IDE подсказывает поля и таблицы
- меньше риска ошибиться в имени таблицы или колонки
- код ближе к SQL, чем при использовании ORM
Практический пример
Будем использовать ту же модель, что и в предыдущих блоках:
usersorders
Например, нам нужно получить всех пользователей по имени:
var users = dsl
.selectFrom(USERS)
.where(USERS.NAME.eq("Alex"))
.fetch();
А теперь более интересный запрос: получить пользователей и количество их заказов.
var result = dsl
.select(
USERS.ID,
USERS.NAME,
count(ORDERS.ID).as("orders_count")
)
.from(USERS)
.leftJoin(ORDERS).on(ORDERS.USER_ID.eq(USERS.ID))
.groupBy(USERS.ID, USERS.NAME)
.fetch();
Такой код очень близок к SQL и хорошо подходит для:
- отчетов
- аналитических запросов
- сложных join-ов
- агрегаций
- запросов, где важно точно понимать, какой SQL будет выполнен
Как подключить jOOQ
Если используется Spring Boot, то обычно подключают starter:
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-jooq'
implementation 'org.postgresql:postgresql'
}
Если нужен code generation, то дополнительно подключают зависимости для генератора и плагин.
Пример build.gradle:
plugins {
id 'java'
id 'org.springframework.boot' version '3.4.5'
id 'io.spring.dependency-management' version '1.1.7'
id 'nu.studer.jooq' version '9.0'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-jooq'
implementation 'org.postgresql:postgresql'
jooqGenerator 'org.postgresql:postgresql'
}
jooq {
version = '3.19.18'
edition = nu.studer.gradle.jooq.JooqEdition.OSS
configurations {
main {
generationTool {
jdbc {
driver = 'org.postgresql.Driver'
url = 'jdbc:postgresql://localhost:5432/app'
user = 'user'
password = 'password'
}
generator {
name = 'org.jooq.codegen.DefaultGenerator'
database {
name = 'org.jooq.meta.postgres.PostgresDatabase'
inputSchema = 'public'
}
target {
packageName = 'com.example.jooq.generated'
directory = 'build/generated-src/jooq/main'
}
}
}
}
}
}
Как настроить подключение к базе
Для работы самого приложения настройки обычно задаются через application.yml:
spring:
datasource:
url: jdbc:postgresql://localhost:5432/app
username: user
password: password
driver-class-name: org.postgresql.Driver
Если используется spring-boot-starter-jooq, Spring автоматически создаст DSLContext, который можно внедрять как bean.
Например:
@Service
public class UserQueryService {
private final DSLContext dsl;
public UserQueryService(DSLContext dsl) {
this.dsl = dsl;
}
public List<String> findNamesByEmailDomain(String domain) {
return dsl
.select(USERS.NAME)
.from(USERS)
.where(USERS.EMAIL.like("%@" + domain))
.fetch(USERS.NAME);
}
}
Как автосгенерировать код по базе
Одна из ключевых возможностей jOOQ — генерация Java-кода по уже существующей схеме базы данных.
Идея такая:
- jOOQ подключается к базе
- читает схему
- генерирует Java-классы для таблиц, полей, ключей и т.д.
После этого в коде можно писать:
USERS.ID
USERS.NAME
ORDERS.USER_ID
а не строковые литералы.
Для генерации обычно используют Gradle-задачу:
./gradlew generateJooq
После выполнения задачи сгенерированные классы появятся в указанной директории, например:
build/generated-src/jooq/main
Эту директорию нужно добавить в source set, если плагин не сделал этого автоматически.
Как выглядит использование в коде
Пример сервиса с простым и более сложным запросом:
@Service
public class UserQueryService {
private final DSLContext dsl;
public UserQueryService(DSLContext dsl) {
this.dsl = dsl;
}
public List<UserRecord> findByName(String name) {
return dsl
.selectFrom(USERS)
.where(USERS.NAME.eq(name))
.fetchInto(UserRecord.class);
}
public Result<Record3<Long, String, Integer>> findUsersWithOrderCount() {
return dsl
.select(
USERS.ID,
USERS.NAME,
count(ORDERS.ID).as("orders_count")
)
.from(USERS)
.leftJoin(ORDERS).on(ORDERS.USER_ID.eq(USERS.ID))
.groupBy(USERS.ID, USERS.NAME)
.fetch();
}
}
Плюсы jOOQ
1. Полный контроль над SQL
Разработчик точно понимает:
- какой запрос будет выполнен
- какие join-ы используются
- какие поля реально выбираются
Это особенно важно в сложных системах и под нагрузкой.
2. Типобезопасность
Если таблица или поле изменились, ошибка часто проявится уже на этапе компиляции, а не в runtime.
3. Отлично подходит для сложных запросов
jOOQ особенно хорош там, где ORM становится неудобным:
- аналитика
- отчеты
- агрегации
- сложные фильтры
- SQL-специфичные конструкции
4. Код ближе к SQL
Это делает поведение системы более предсказуемым.
Минусы jOOQ
1. Нужно хорошо понимать SQL
Если ORM позволяет часть деталей скрыть, то jOOQ, наоборот, требует уверенного понимания:
- join
- group by
- aggregation
- subquery
- execution plan
2. Больше кода для простых CRUD-сценариев
Для простого приложения с базовыми сущностями Spring Data JPA часто оказывается быстрее и удобнее.
3. Нет ORM-абстракции
jOOQ не решает автоматически задачи:
- object graph mapping
- lifecycle сущностей
- dirty checking
- persistence context
Когда jOOQ особенно уместен
jOOQ хорошо подходит, если:
- запросы сложные и SQL-доминирующие
- важен контроль над производительностью
- нужны отчеты и аналитические выборки
- ORM начинает мешать, а не помогать
Во многих реальных проектах jOOQ используется вместе с Hibernate / JPA:
- JPA — для CRUD и простых доменных сценариев
- jOOQ — для сложных запросов и аналитики
8. Trade-offs
Выбор инструмента — это выбор уровня абстракции.
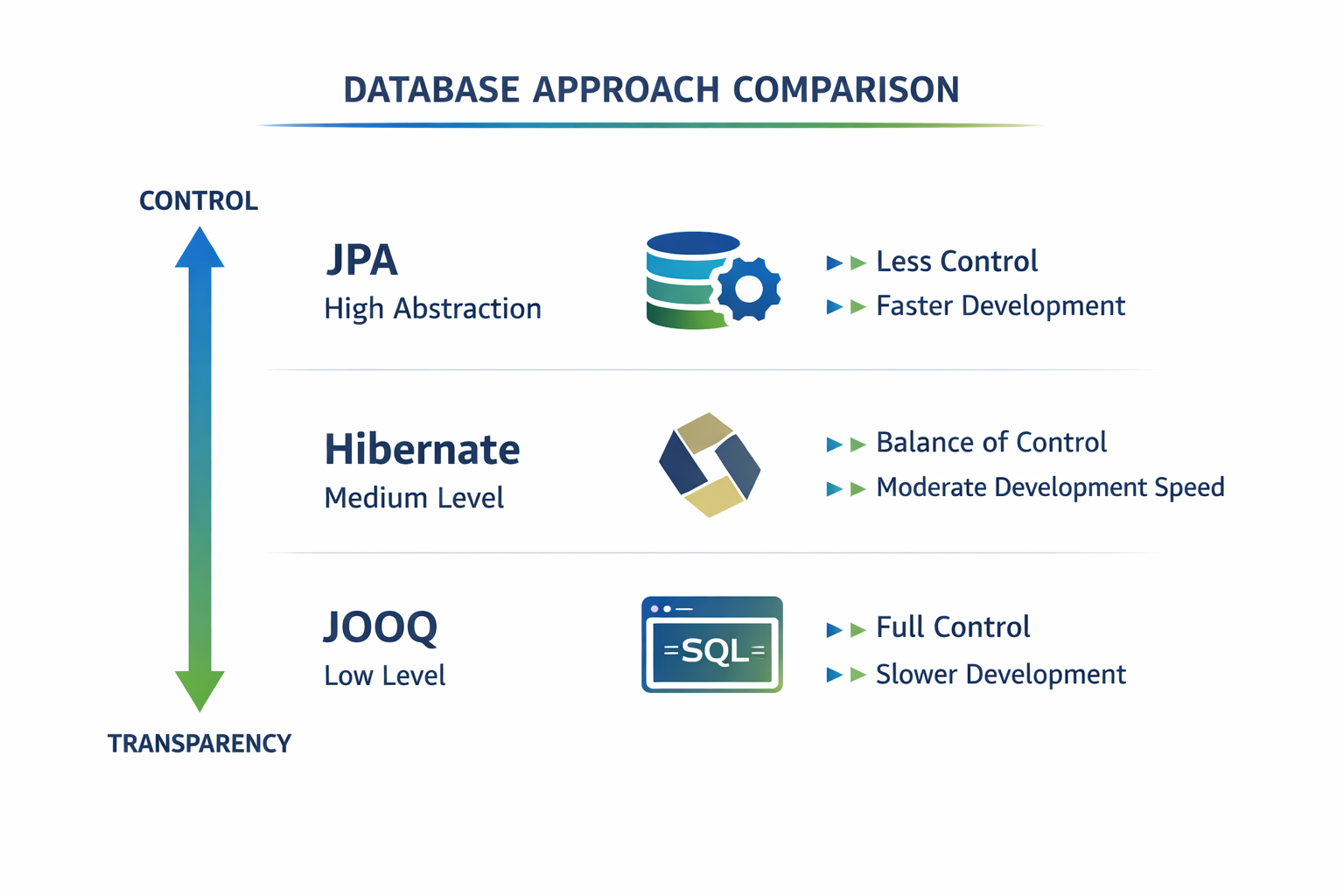
| Подход | Контроль | Скорость | Сложность |
|---|---|---|---|
| JPA | низкий | высокая | средняя |
| Hibernate | средний | средняя | высокая |
| JOOQ | высокий | ниже | средняя |
На практике выбор между JPA/Hibernate и jOOQ редко бывает абсолютным. Во многих системах ORM используют для типового CRUD и доменных сценариев, а jOOQ — для сложных запросов, аналитики и участков, где особенно важен контроль над SQL. Поэтому вопрос обычно звучит не “что лучше вообще”, а “какой уровень абстракции подходит для этой конкретной задачи”.
Итог
- ORM решает фундаментальную проблему несоответствия моделей
- JPA задает правила
- Hibernate реализует их
- Spring упрощает использование
- JOOQ дает контроль
В реальных системах часто используется комбинация подходов.